Index Coverage from Google’s New Search Console
We all have got access to the much-awaited New Search Console (available at https://search.google.com/search-console).
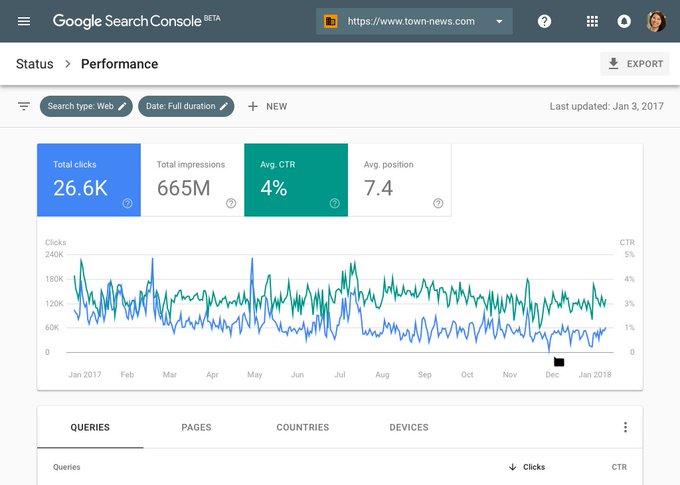
While the new features are in the development stage, we already have access to couple of great ones. The first one is of course the Performance section that provides data for 16 months!
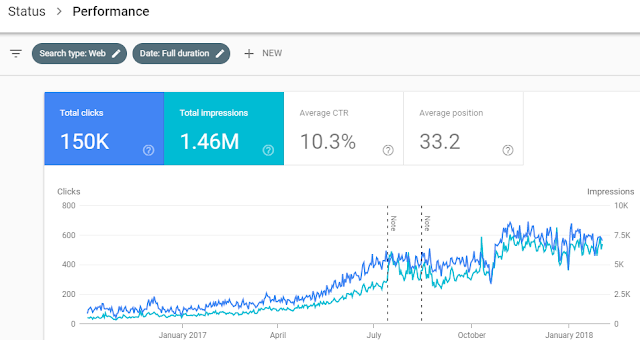
And the second one is Index Coverage.
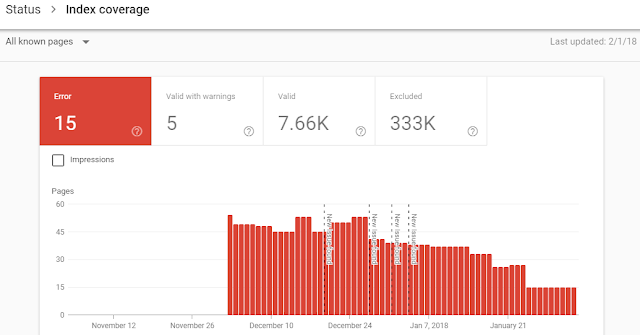
Once you open the Index Coverage report you would find loads of details that includes the following:
Errors – Pages that couldn’t be indexed for some reasons.
Valid with Warnings – Pages that are indexed but with some issues and Google isn’t sure if they are intentional at your part. Example – Tag pages on your blog.
https://www.example.com/blog/tag/seeds/
Valid – Pages that are indexed without any issues.
Excluded – Pages that were intentionally not indexed.
Now under Excluded you would see various reasons due to which Google didn’t index some pages of your site.
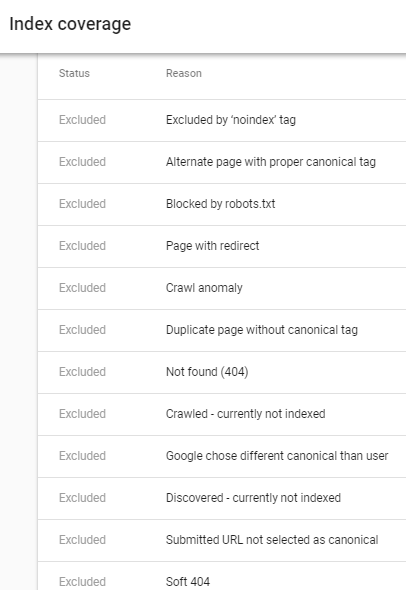
Google chose different Canonical than user
I tried to find some excluded URLs under this reason and was amused to know how smart Google is. Will try to present my learning with a simplified example here:-
Assume I have an ecommerce site https://www.example.com with a sub-category page https://www.example.com/seeds/fruit-seeds.html
Under this category I have a lot of products that I serve using Pagination. Let’s assume 20 products on each page and following is the URL structure:
https://www.example.com/seeds/fruit-seeds.html
https://www.example.com/seeds/fruit-seeds.html?p=2
https://www.example.com/seeds/fruit-seeds.html?p=3
https://www.example.com/seeds/fruit-seeds.html?p=4

I have perfectly set up the Pagination with the required rel next/prev and rel canonical tags. (Refer to Glenn Gabe’s excellent article on how to set up the Pagination properly.)
All these pages present unique products and hence I have implemented self-referencing canonical tags on these pages rather than pages from p=2 to p=4 having a canonical tag that points to the main page /fruit-seeds.html
Now just imagine somewhere down the line, I am left with just 15 products.
That means the main page https://www.example.com/seeds/fruit-seeds.html is enough to serve all these products. But the other pages, p=2 to p=4 are still present in Google’s index with a self-referencing canonical tag and if I try to check these pages, they all show the same 15 products that are actually available on the main page.
While my canonical tags are telling Google that pages p=2 to p=4 have self canonical tags but Google is smart enough to understand that those pages are now showing the same products as the main page and it has to disregard my canonical tag. Hence it chooses different canonical and excludes p=2 to p=4 pages from the index. And it only shows https://www.example.com/seeds/fruit-seeds.html in the index.
How to check this?
Once you navigate to ‘Google chose different canonical than user’ under Index Coverage, you would see a list of URLs that were excluded from index. Click on any of those pages and you would see Page details that open on the right:
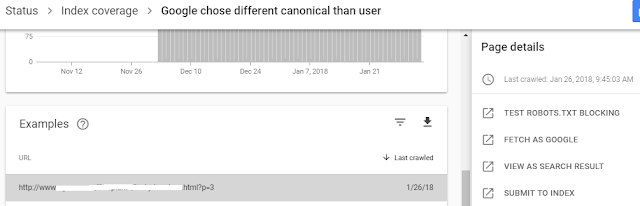
Click on View as Search Result.
You would see the page that Google considered as canonical.
So basically you would see search modifier ‘info:’ followed by the excluded URL and as result you would see the canonical version Google preferred to index.
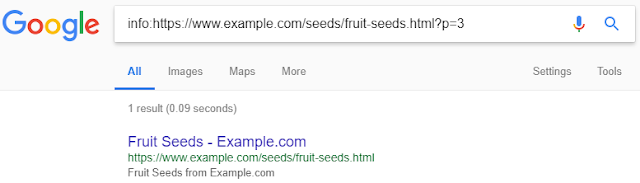
That’s really smart. And this also proves rel canonical is a HINT and not a DIRECTIVE.
Comprehensive details on the Index Coverage Status Report is available here: