What is Crawl Budget?
Crawl Budget is a good old concept often overlooked by the search engine optimisation experts. While we all keep pondering on how good the title tags need to be or how to optimise the images; we often forget about how easy or difficult the crawler journey would be on our site?
Search engine crawlers, spiders or bots are basically programs that visit your site continuously, collect information and create a search engine index. While we emphasise on the user friendliness of our sites, we overlook the importance to make a crawler’s journey amicable on our site.
In a recent post on Google Webmaster Central Blog, Gary Illyes tried to explain What Crawl Budget Means to Googlebots. And this is how the post simply defines Crawl Budget – The number of URLs Googlebot can and wants to crawl on your site.
Understanding Crawl Budget further
Although Google hasn’t mentioned how to quantify Crawl Budget, just to get a rough estimate we can assume the following:-
On an average, if Googlebot crawls 100 pages every day on my site, the monthly crawl budget should be 100*30 = 3000.
Determine Crawl Budget using Google Search Console
Sign into your Google Search Console account, visit the Crawl Stats subtab under Crawl. This is what you would see
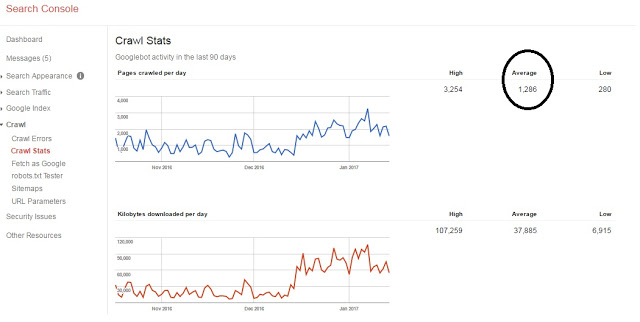
In this example, the average number of pages crawled in last 90 days by Googlebot were 1,286. So monthly crawl budget comes out to be 1,286*30 = 38,580.
Who should prioritize crawl budget?
- If your new pages are being crawled the same day, you can don’t need to worry much about the crawl budget
- If your site has fewer than a few thousand pages, ideally your site would be crawled efficiently. Crawl budget isn’t a cause of concern here
- You should certainly pay a lot of attention to crawl budget if your site is huge in size where you need to prioritize important pages. Or you own a site that auto generates pages with URL parameters that doesn’t change the content.
Crawl rate limit and Crawl demand
Googlebot crawls the websites to gather information and create a search engine index. Google takes cares that the overall crawling process shouldn’t hamper the experience of users that visit the site. Hence it has to set a limit on how often and how long should it crawl a site. This is called Crawl rate limit.
Gary Illyes included couple of important factors in his post that could affect the crawl rate. They are as follows:
- Crawl health – The crawl rate can go high if the site responds quickly. The rate may go down if the site is slow or throws server errors.
- Crawl limit set in Search Console – The crawl rate can be affected if the site owners have modified the crawl rate in Search Console. Note new crawl rate that you set in the Search Console is valid for 90 days.
The crawl rate can also depend on the demand to crawl certain pages of your site. At times, even when the crawl limit isn’t reached, Googlebot would be disinterested in crawling your pages if there is no demand from indexing. Crawl demand can be determined from the following three factors:
- Site/page popularity – Googlebots prefer to crawl popular pages more. This is an effort to keep those pages fresh in the Google index.
- Staleness – Googlebots prefer to prevent pages from becoming stale in the index.
- Site-wide events – In cases where your site undergoes a revamp or moves to another domain, bots would prefer to recrawl and reindex the site pages to keep its index fresh.
Why to optimise your Crawl Budget?
Now we understand what exactly is a crawl budget. And probably we all have a certain crawl budget assigned to our site which in turn depends on numerous factors such as the site size, site health, authority, popularity and many more to name.
How about a scenario where Googlebots are absolutely not interested in crawling your site even if they haven’t reached the crawl rate limit? Probably because your site is technically unhealthy! Loads of crawl errors, duplicate content, dynamically generated URLs and what not!

Now that’s a tough situation!
If you really want Google to discover your important content and that too quite frequently, you need to optimise the crawl budget of your site. Logically this is possible if you improve the crawl rate limit and crawl demand for your site.
To prove this point let’s revisit the definition of crawl budget:- The number of URLs Googlebot can and wants to crawl on your site.
This can very well mean – Googlebots wanted to crawl say 1000 pages but due to your unhealthy website, they could just crawl 700 live pages. Rest all lead to errors? Or they could just crawl 200 important pages and rest all were duplicate/dynamically generated versions of those 200 pages?
You wasted a large chunk of your website’s crawl budget due to those error pages or dynamically generated duplicate pages on your site.
How to optimize your Crawl Budget?
Now that you know why it is important to optimise the crawl budget, let’s learn how to optimise the crawl budget.
I have tried to list down as many factors as possible that can improve your crawl budget.
1) Make your important pages accessible to Google
Even if you have loads of pages on your site, you would certainly have certain pages that you consider important. For an e-commerce sites, the important pages have to be the home page, category page, sub-category pages, product pages, etc. Just make sure none of your important pages are blocked for Googlebots. Not to forget, you should also allow Googlebots to crawl the CSS and Javascript files. This helps the bots to render your pages correctly.
2) Block pages that are not important
Your site can have pages with duplicate content, very old news articles, dynamically generated pages that add no value to the site, etc. Make sure you block such pages in robots file. Preferably add a noindex tag to such pages so that they aren’t a part of the Google index.
I have seen several instances where sites are developed on test domains that aren’t blocked for Google. The bots crawl and index such test sites. Once the actual site is launched, the test domain leads to duplicate content. Our motive should be to block pages that are not important so that Googlebots can assign crawl budget to the right pages!
3) Avoid redirect chains
Long redirect chains can create two issues. First, Googlebots might drop off before they reach your destination URL. This could lead to suboptimal rankings. Second, for every redirect the bot follows; it wastes a bit of your crawl budget.
So unless and until it is not very important, avoid long redirect chains on your site.
4) Broken links
Broken links lead bots and users to a page that is of no use. This is another way to waste a unit of your crawl budget. Avoid broken links.
5) Update your sitemaps regularly
There is a high probability that you leave behind URLs in the sitemap that are no longer important or no longer exist on the site. Googlebots can use your sitemap as a medium to crawl your site pages. Make it a habit to remove the unimportant pages from your sitemap and don’t forget to add the new and important pages.
Additionally you can add your sitemap link to the robots.txt file. Since Googlebots prefer to visit the robots file first, they would come across your sitemap link and crawl all the important pages from there.
6) Manage parameters on dynamic URLs
Your site platform or CMS could be generating a lot of dynamic pages. This could potentially lead to duplicate content and harm your site performance in search engines. This could also waste more bit of your crawl budget.
If parameters added to your URLs don’t influence the content of the pages; inform Googlebots about this by adding these parameters in your Webmaster Tools account (Google Search Console). You can find the subtab URL Parameters under Crawl in your search console.
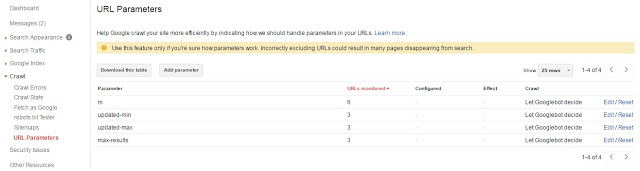
If parameters added to your URLs don’t influence the content of the pages; inform Googlebots about this by adding these parameters in your Webmaster Tools account (Google Search Console). You can find the subtab URL Parameters under Crawl in your search console.
7) Manage your site structure and internal links well
Plan your website structure well. Have a well set hierarchy that not only helps users freely navigate through your site but also provides an ease of navigation to the bots. Try to keep important pages not more than three clicks away from any page. Add most important pages/categories/sub-categories in your navigation menu.
Internal links might not be a very big factor here, but it is an integral part of a good site hygiene. It can also work in favour of bots to follow the internal links and lead to important pages you wish to get crawled.
8) Pay attention to Crawl Errors section in Search Console
As mentioned in Gary’s post, one should keep a constant check on the crawl errors found in the search console. Try to fix as many errors as possible (that includes server errors, soft 404, not found, etc). This would help bots avoid wasting every single bit of the crawl budget on such error pages.
9) Good and Fresh content
This is a must. Not only for a better crawl budget but also for your overall site performance. Avoid low quality and spam content. That’s not going to help. Bots would love to crawl your site more frequently if you add more and more fresh and valuable content on your site. After all it’s bots’ duty to keep the Google index fresh!
10) Build ‘good’ external links
We all know content and links are the top two factors to rank our sites well. How would external links contribute to a better crawl budget? It’s pretty simple. Logically more links you own from authority sites, more would be the chances of crawlers revisiting your site. Few experiments carried out by industry experts has proved that there is a strong correlation between the number of external links and number of bot visits to your site.
11) Work on your site speed
Users always prefer to visit fast loading websites. Similarly a speedy site improves the crawling rate. Make use of some important Google tools to regularly determine the speed of your site pages and recommendations on how to make them load faster.
https://developers.google.com/speed/pagespeed/insights/
https://testmysite.thinkwithgoogle.com/
Once you take care of all these factors you can certainly expect a happy Googlebot. One like this:

You might also wanna check Mobile Optimization.